













































































263
101
嵌入 LLM 大模型,OriginOS 4 带来什么变化?
2023-11-01 15:27:26
0点赞
0收藏
0评论
像 OriginOS 这样的手机 OS 全面导入 AI 大模型应用带来的改变是多方面的。
手机操作系统引入人工智能并非新鲜事,但是这次的意义真的非同凡响。在过去手机 AI 主要是一些语音指令、用户操作响应优化、影像等后台应用,虽然能带来直观变化感受,但是就用户体验而言,交互体验并不大,像语音指令其实只是用来协助操作手机,它并不能理解、回答复杂的问题。
但是这次大模型却是很不一样,大家可以透过文本、语音等自然语言的方式让 AI 完成各种处理,涵盖了生活、工作、学习等场景,OriginOS 的 AI 可以对用户提出的许多问题提供有价值的参考建议、内容创作,按照用户提供的资料进行数据挖掘、清理形成内容更清晰的文档。
最大变化是LLM 应用变得前所未有的方便。
在 OriginOS 中内置 LLM 应用(小 V 助手)后,最大的变化是使用更方便了,特别是不少像我这样的 LLM 重度依赖用户。
不管是海外还是国内的 LLM 应用,为了达到最好的效果,都会采用规模极大的模型,超出了大多数台式机的能力更不要提手机了,所以 LLM 应用目前基本都是部署在云端。
深度学习模型计算可以分为训练和推断,前者是用于构建包含大量网络化参数的模型,而后者则是利用这个模型对用户输入进行响应并给出答案。
模型里包含的网络化参数越多,相当于脑细胞越多,思维能力越强,像 GPT-3 就有 175B(1750 亿)个网络参数,基于 GPT-3 衍生的大模型让人们意识到 AI 具备非常出色的对话能力,而且在很多情况下都比人类更出色。
只不过这一切都是有代价的。
GPT-3 的网络参数规模是 1750 亿,执行推断所需要的内存规模会达到百 GiB 级别,目前整套东西弄下来的成本达到 100 万元级别,且不说你能不能抢到相应的硬件资源,光是自己搭配起来也不是一件轻松的事情。
另一方面,手机已经是大家寸步不离的随身设备,使用非常方便,但是毕竟处理器性能、内存容量的约束摆在那里,如果要在手机上部署端侧模型,其规模和精度必须做不少调整。
像 OriginOS 4 这样将 LLM 应用(小 V 助手)集成到手机操作系统后,使用起来将会非常便捷,特别是人工智能文档资料处理、文案生成、语言翻译,在手机里可以随时召唤出来。
和知乎上很多人都实际体验过海外那个 chat 不同的是,我虽然尝试过很多次注册,但是实在搞不定,想给送钱给它也不容易。在这半年里我是用的不过是那个有 4000 字符限制的 New Bing,这东西虽然是一个缩水版,但是对我来说的确帮助很大,例如测试脚本的编写,效率比我手工编写高得多,而且它对脚本的除错能力也比较强,很多我平常没注意的代码技巧它都能即点即用。可以说没有这类工具帮忙的话,我写的部分文章测试项目完成效率会大大降低。
所以我对 AIGC 型的 LLM 应用非常看好,相信将这类应用嵌入到手机操作系统后,定比会给大家的学习、工作、日常生活带来巨大的便利。
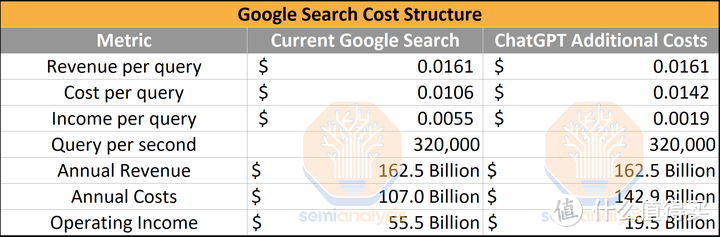
资料来源:The Inference Cost Of Search Disruption – Large Language Model Cost Analysis (semianalysis.com)
LLM 如此好,但是正如前面所提到的,它的实现成本相当高。LLM 在商用方面的主要成本是在推断上,推断的成本远高于模型训练。像谷歌每次搜索的成本大约是 1.06 美分,而那个最多人津津乐道的某 chat 执行推断查询时的成本据闻是 1.42 美分,按照每秒 32000 次查询操作计算成本的话,一年起码得 1429 亿美刀。当然,随着时间的推移技术的进步,相关成本很可能会在不久后就快速下降。
现在手机的净利水平一般也就是 10% 甚至不到,要实现 LLM 的话很可能会对盈利构成不少压力,因此在真正落地的时候,厂商会针对不同的应用需求提供不同规模的模型。

按照这次 vivo 开发者大会上的资料,这次他们选择了多模型技术,包括了能在云端和手机端部署的 70 亿参数 LLM,,也有能直接部署在手机端的 10 亿参数轻量级视觉大模型,更有高达 700 亿、1300亿以及 1750 亿参数的云端大模型,其中的 70 亿参数模型 BlueLLM(蓝心模型)已经在 github 上开源。
 vivo 已经在 github 和 Hugging Face 将蓝心模型 70B 开源上传
vivo 已经在 github 和 Hugging Face 将蓝心模型 70B 开源上传 在多个榜单上屠榜
在多个榜单上屠榜这样的多模型方式不仅能满足不同应用场景,而且成本效益比上要比单个超大模型划算不少,实现秒级响应的同时还能避免日常应用往云端上传隐私数据的问题,只有在遇到复杂要求的时候,才会跑到 vivo 的云端生成响应,做到端侧和云侧协同运作。
这次 OriginOS4 第一波内测手机包括了 X90 Pro+ 等旗舰机型,提供的 LLM 应用是还是纯云端,稍后的新机型发布时有可能会提供一个端侧模型应用(基于 10 亿参数的蓝心端侧大模型),能用于文本总结。
 10 亿级别的端侧模型特点
10 亿级别的端侧模型特点本来 vivo 这边发了一台专门用于 OriginOS 4 的测试样机,但是时间上赶不上趟了,所以我找了楠爷让他帮忙测试一下,算是一种云体验了。
首先来个代码解读吧。
这里篇幅有限,扔一大段代码上来的话估计会劝退不少人,所以我决定来个简单一点的,就用我平时跑测试时经常用到的一条指令:
k10=192.168.2.178 bash -c 'adb connect $k10:$(sudo nmap $k10 -p 35000-47000 -sS -oG - --defeat-rst-ratelimit | awk "/open/{print $5}" | cut -d/ -f1)'
这是一条 Linux 指令,里面有变量赋值、sudo、adb、nmap、awk 等指令,对于只用过 Windows、手机等图形系统的普通用户来说肯定蒙圈,即使是 Linux 用户也不见得能马上明白其用途。
这条指令和我最近做的事情密切相关。
因为需要测试不少手机处理器微架构的缘故,我需要经常透过 adb 和手机连接,USB 线比较麻烦,而且无法用于功耗测试,所以我现在都是用 adb 无线调试模式连接手机。
安卓手机的无线调试在重新连接网络或者重启手机后,虽然 IP 地址不变,但是端口会随机变化。因此我无线调试的时候可能需要打开手机,打开开发者选项,打开无线调试模式,找到里面的端口数值,相当繁琐,上面这条指令则可以在 10 秒左右扫描出手机的开放端口并自动连接上,省去了不少麻烦。
把这条指令扔给小 V 助手后,它提供的解读如下:

作为对比,我找来了号称基于 GPT-4 的 New Bing 作为对比:
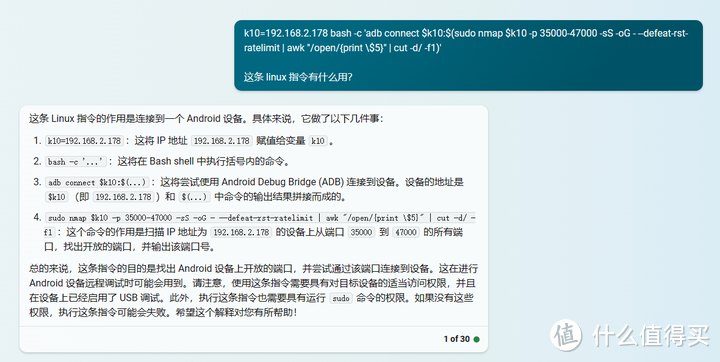
从回应的答案来看,两者还是比较接近的,回答质量我觉得都行,只是侧重点可能有点不一样,小 V 助手偏向于逐个指令的解读,而 New Bing 偏向于分段解释指令,对我来说其实都是可以接受的答案。
对码农来说,一般都不喜欢在手机上敲代码,毕竟屏幕太小了,触控式操作也容易犯错导致效率低下,但是像上面这种对一些看似复杂、代码量不大的指令进行解读还是比较有价值的应用。
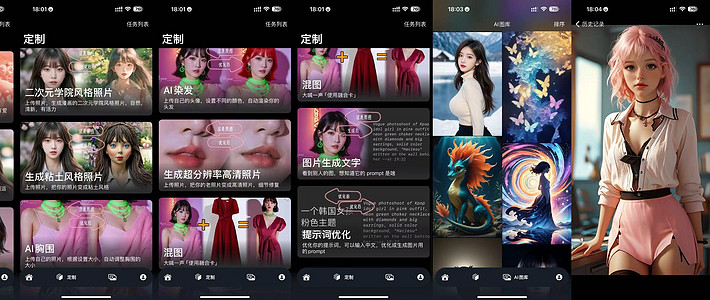
接下来我又到 civitai 的[SDXL] RongHua | 容华 | 国风大模型模型页面上找来了一张图片,想试试看图生图的效果,这是原图(作者是 yi_yu):

然后扔给小 v 助手,让它使用日本动漫风格生成几张图片:
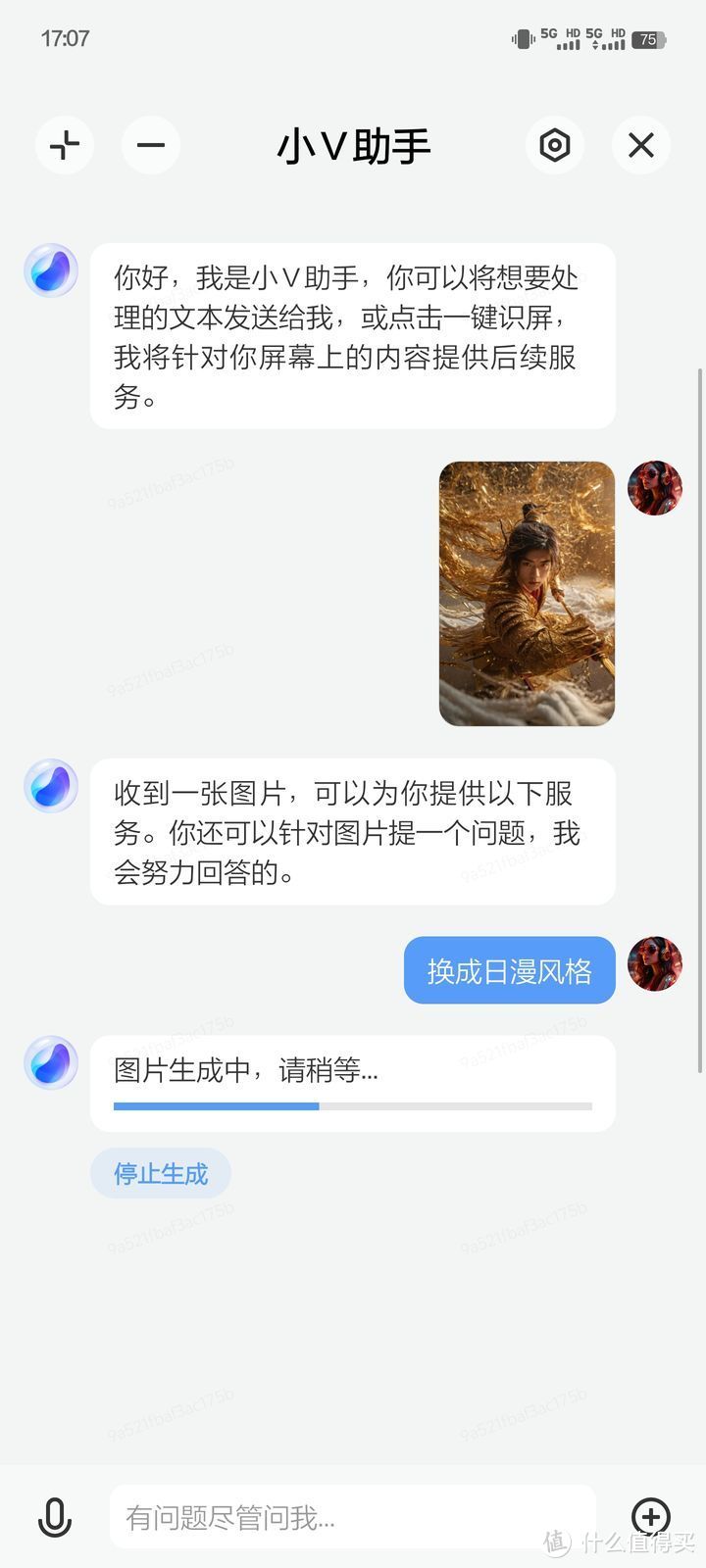
图片计算是在云端执行,几秒就完成了:




哎呀呀,这效果有点出乎意料呀,画风和原图非常接近,姿态、眼神、服饰都不错,当然细究的话,肯定还是有一点不足(例如第二张图似乎有点粗糙),但是要是让我画的话,以我的灵魂画师能力估计一辈子都画不出来。
接下来我还尝试了一下生成小红书文档,方法就是扔一张我拍的照片给它,让它为这张图片生成小红书文案。
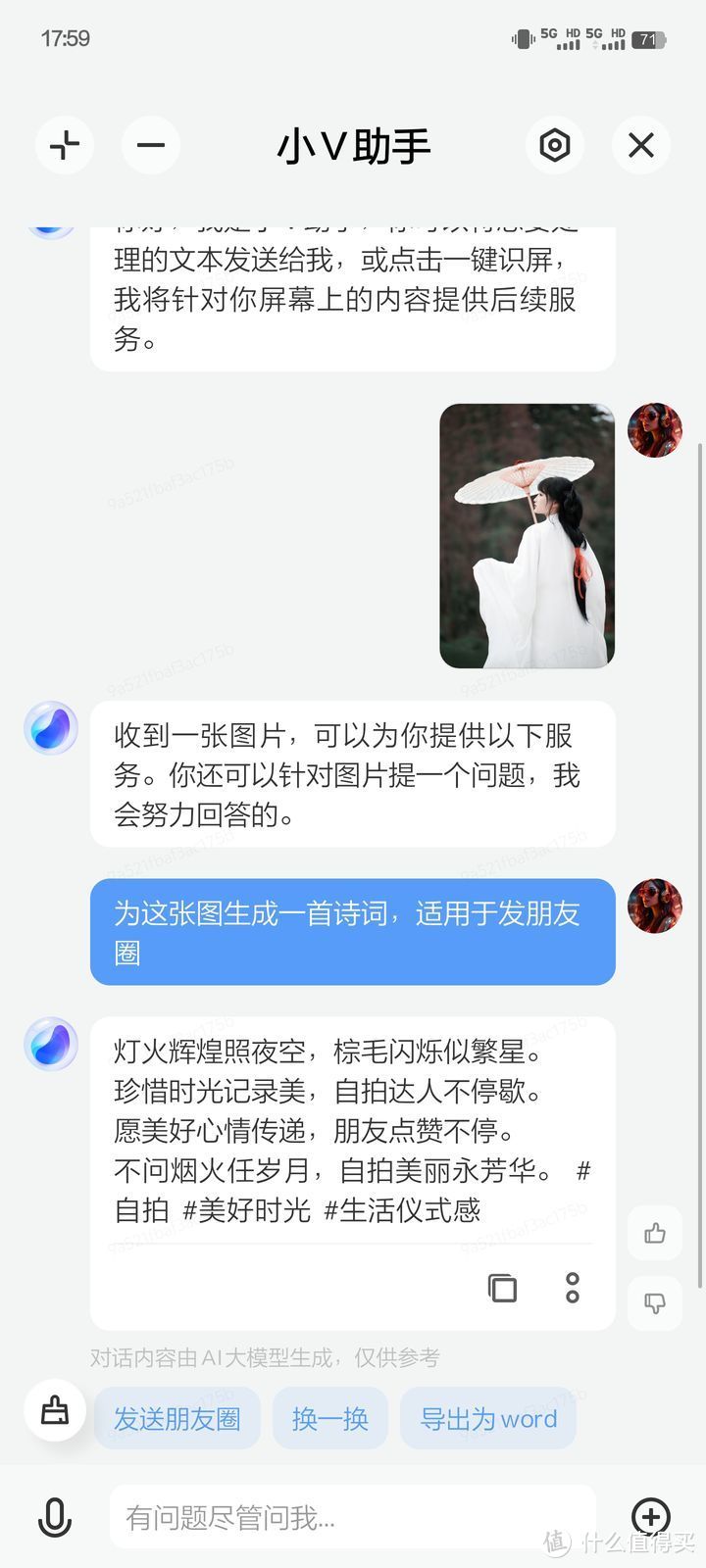
这次出状况了,小 v 助手好像并不能完全理解图片的内容,灯火、星空等不相干的文字冒出来饿了,然后还有棕毛闪烁似繁星这样莫名其妙的语句,从文案的角度来看是不能使用的,这应该和图片内容解读、诗词能力有关,考虑到这次还只是初测,出现这种情况倒是可以理解,所幸 AI 模型在以后是可以不断训练完善的。
vivo 提供了一个有 100 个小 v 助手应用场景的介绍文档,里面都是相应的录像,其中有包括活动方、视频拍摄方案、辩论观点等思维导图的生成、英文论文全文翻译、创建日志并写发言稿、文本创作+保存+重命名等都属于小 v 助手的独家功能,我都逐个看了,的确是比较有意思的实用场景。
由于手头没有实机只能借楠爷这边云测,所以这次测试的体验还是比较有限的,从测试结果来看,小 v 助手(其实是调用蓝心千洵)的代码解读能力还是比较出色的,图片生成能力也不错,但是图片解读后的诗词创作能力比较有限,当然,就目前而言,AI 对古诗词的能力我就没看到过哪个很出色。

最后总结一下,这次 OriginOS 4 更新提供的小 v 助手可以算是在手机上实现了大型语言模型从 0 到 1 的嵌入式应用突破,而且这个 1 的涵盖面比较大,例如前面提到的 100 个小 v 助手应用场景,涵盖了学习、工作、生活的方方面面。
比较特别的是,OriginOS 4 或者说 vivo 的 LLM 选择了多模型方案,端、云部署结合,这是很值得肯定的,从成本效益和用户私密角度看,这样的方案应该是最优解。

vivo 开发者大会上宣布蓝心千询 app 适用于所有手机

LLM 或者说大型语言模型为大家提供了前所未有的 AI 使用体验,特别是手机这类随身产品,能做到拧起即用,谁能为用户带来更好的 LLM 体验,谁就能在未来的竞争中获得更多的用户,相信大家也会乐见这方面的百花齐放。
本文原发于知乎。















