










































































261
99
使用技巧 篇十二:AI生成物理准确的3D数据!Omniverse Replicator
2023-10-28 07:44:41
4点赞
4收藏
0评论
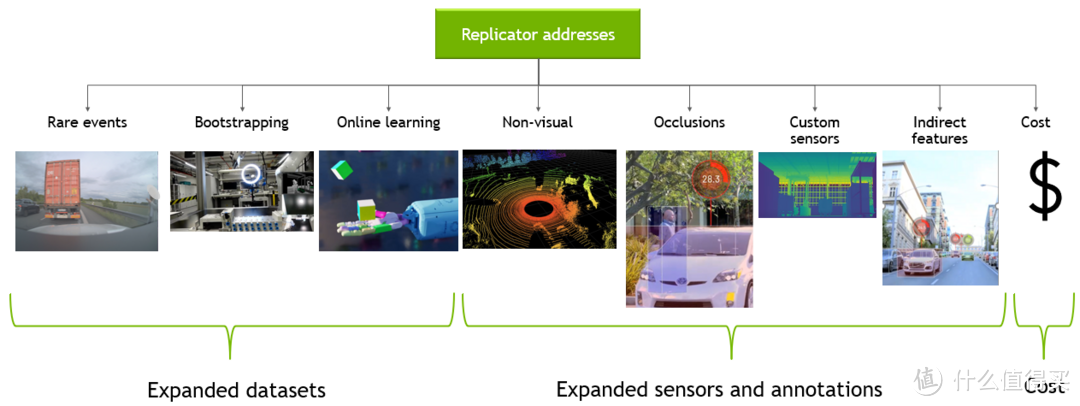
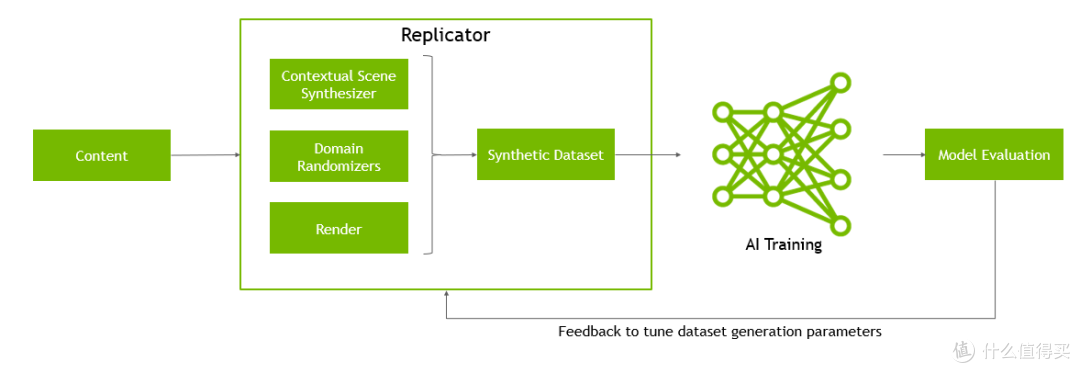
Omniverse Replicator是建立在可扩展的Omniverse平台上的框架,用于加速AI感知网络的培训和性能。它允许生成物理准确的3D合成数据,用于训练和改进现有模型,或开发以前由于缺乏数据集或所需注释而无法实现的新模型。
Replicator提供了一组工具和工作流,帮助深度学习工程师和研究人员启动模型训练,提高现有模型性能,或创建以前无法获得的新类型的数据集和注释。
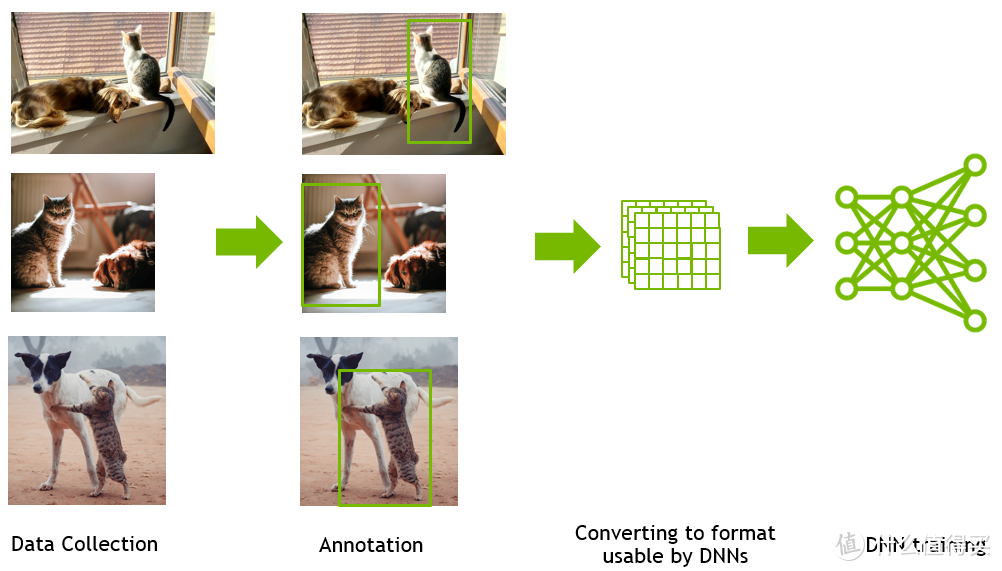
核心功能:
Semantics Schema Editor(语义模式编辑器): 提供语义标签,用于识别场景中需要边界框、姿势等注释的对象。
Visualizer(可视化工具): 用于可视化2D/3D边界框、法线、深度等语义标签。
Randomizers(随机化工具): 快速从资产、材质、照明和摄像机位置中进行随机化,创造多样性。
omni.syntheticdata(低级组件): 与RTX渲染器和OmniGraph计算图系统集成,为Replicator的Ground Truth提取提供支持。
Annotators(标注系统): 用于处理从omni.syntheticdata扩展中提取的信息,生成准确标记的注释,用于DNN训练。
Writers(写入器): 处理来自标注器的图像和其他注释,生成用于训练的DNN特定数据格式。
学习资源:
Python API文档: Omniverse Replicator的Python API文档提供了详细信息。
变更日志: Omniverse Replicator的变更日志提供了详细的更新信息。
教程: Omniverse提供了一系列教程,帮助你快速入门使用Replicator。包括基本操作、相机控制、随机化、注释系统、自定义写入器等内容。
Github示例: Omniverse在Github上提供了Replicator的示例代码,包括代码片段、完整脚本和USD场景,以及YAML脚本的使用说明。
云端使用: 提供了在云端设置Replicator的说明,包括容器设置、AWS配置等。
请注意,Replicator的使用需要面对合成数据训练中的挑战,包括外观差异和内容差异等,需要使用领域随机化等方法来克服。为了成功训练网络,需要在真实数据集上进行测试和调整。整个训练过程是高度迭代的,Replicator允许用户在训练中对场景进行修改、随机化和迭代。















