


































































312
127
实践出真知!100TB的RAID5到底能否重建成功?
2019-04-04 18:40:37
420点赞
1067收藏
432评论
背景
随时近年来家用NAS的不断普及,越来越多的家庭选择NAS作为数据存储与备份、影音数据库搭建以及协同办公等方案的核心设备。而对于一台多盘位的NAS来说,如何来选择一种适用于自己,同时又兼具安全可靠的磁盘存储方式也是一直困扰着大家的问题。笔者在组建NAS时也纠结于此很久,综合考虑自身使用情况后,最后选择只能承受一块硬盘损坏冗余的RAID5形式。由于笔者的技术水平有限,也非专业人员,不具备进行大量技术阐述和评测的水平,因此也不对RAID5的安全性作评价,只想通过一个实验来向值友展示100TB的RAID5到底能否重建成功,重建时间需要多久,以供大家参考。
必要性

笔者的处女作在发表后得到了广大值友的关注和支持,同时笔者也在和大家的交流中学到了诸如ZFS、ceph以及磁带机等数据储存方式的知识,在此深表感谢。笔者在浏览文章评论时,也注意到大家讨论和吐槽最多的地方,就是笔者选用的10TB*12的RAID5存储方式的安全性(见图1),其中关键词最多的就是“不具有可修复性”、“重建时间久”、“重建必然失败”,令人谈“5”色变,俨然就是一个数据火葬场。那么,RAID5到底有这么糟糕吗?
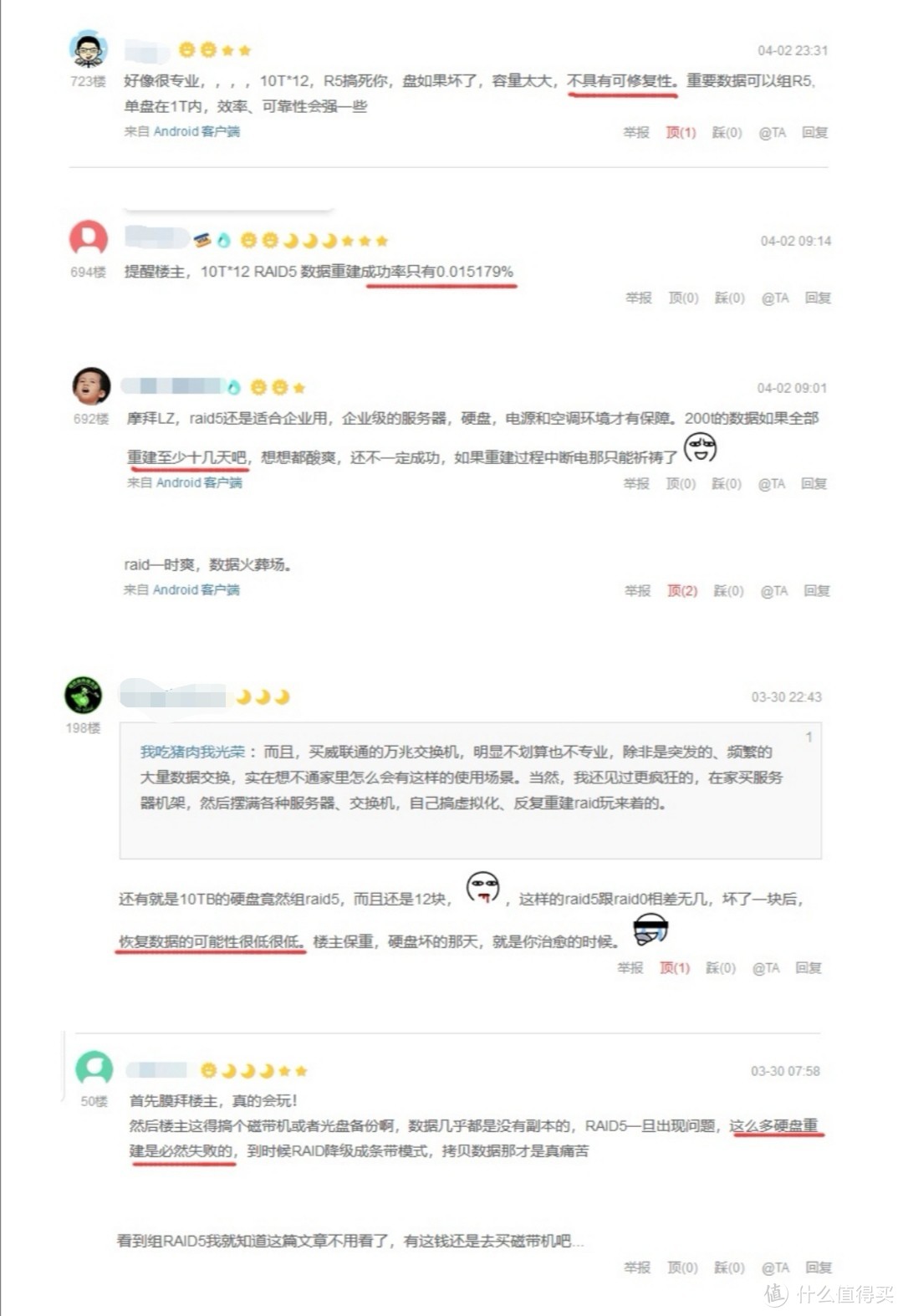 图1 值友对RAID5的评论
图1 值友对RAID5的评论
笔者首先感谢各位值友对我数据存储的关心以及善意的提醒,类似这些关于RAID5的评价笔者在前期调研时也常常在其他地方看到。但是我相信90%的发表这些评论的值友和我一样,并没有重建过RAID5的实操经验,而99.99%的值友更没有重建过10TB*12这种百TB级的RAID5,这些信息也只是来源于口耳相传或者理论计算。笔者同样也没有RAID5重建的经验,因此无法判断这些说法的可靠性。出于好奇心,也为了给大家多一点实战经验作为参考,成为那0.01%的人,笔者决定舍命陪君子,进行一次破坏性实验以验证100TB级的RAID5到底是否具有可修复性、重建时间是否真的要十几天之久或者重建成功率是否只有相当于双色球三等奖的水平。
实验条件
实验用的平台是16盘位QNAP的TS-1635AX,硬盘采用WD Elements 10TB拆机盘WD100EMAZ氦气盘12块。
 QNAP TS-1635AX
QNAP TS-1635AX
 主角 WD100EMAZ氦气盘12块
主角 WD100EMAZ氦气盘12块
实验对象为利用QNAP TS-1635AX组建的12块10TB RAID5,逻辑分区为单一静态卷,实际容量约为100TB,已用空间85.3TB,全部为视频数据。
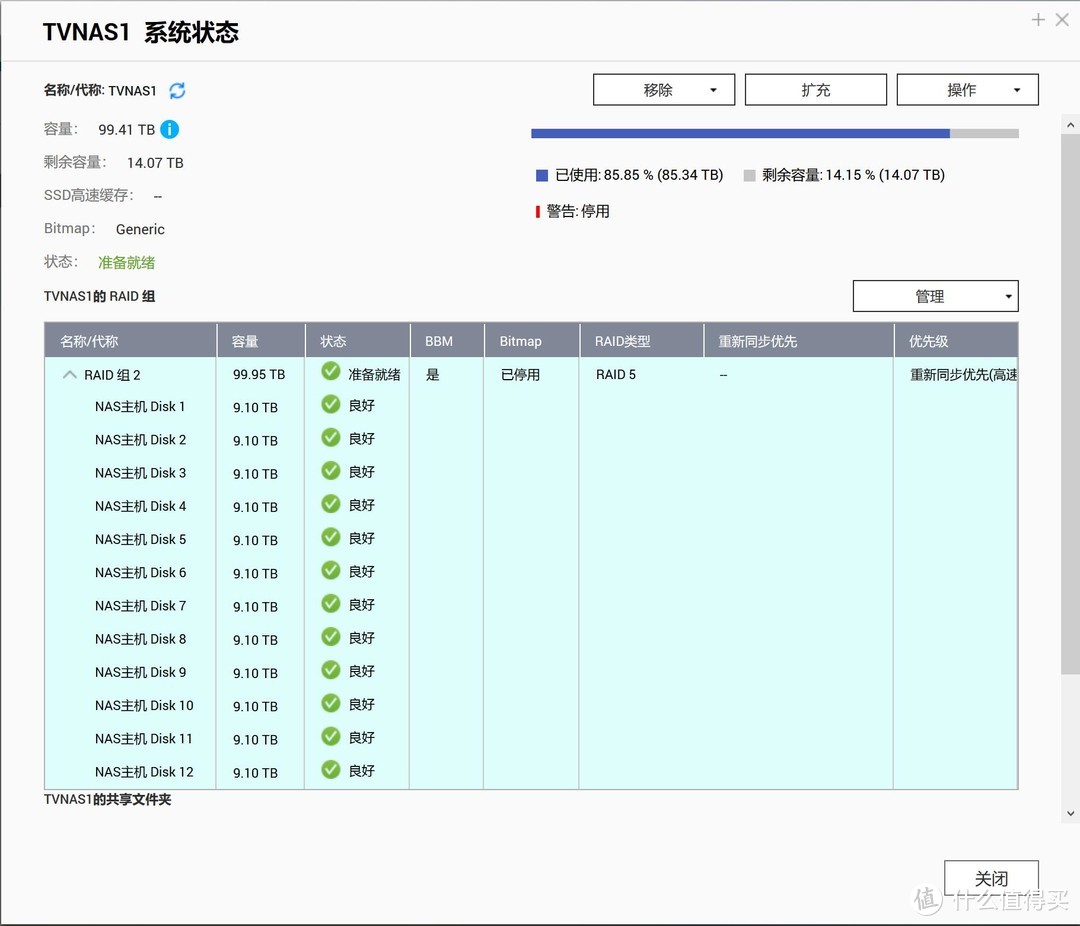

实施过程
为了模拟RAID故障,笔者通过在NAS关机时,随机拔掉其中一块硬盘来模拟RAID中一块硬盘下线的情景。重新开机后,NAS提示一块硬盘发生故障,RAID进入降级运行模式。注意:这种降级模式下,RAID上的数据仍可进行读写操作,但是由于冗余硬盘已损坏,RAID已处于非常脆弱的状况,此时应该立即停止读写作业,更换硬盘启动数据重建程序。如果有条件和技术能力的,可利用专业软件将全部硬盘进行数据镜像(即克隆)再进行重建作业,以防万一。
 提示一块硬盘故障
提示一块硬盘故障
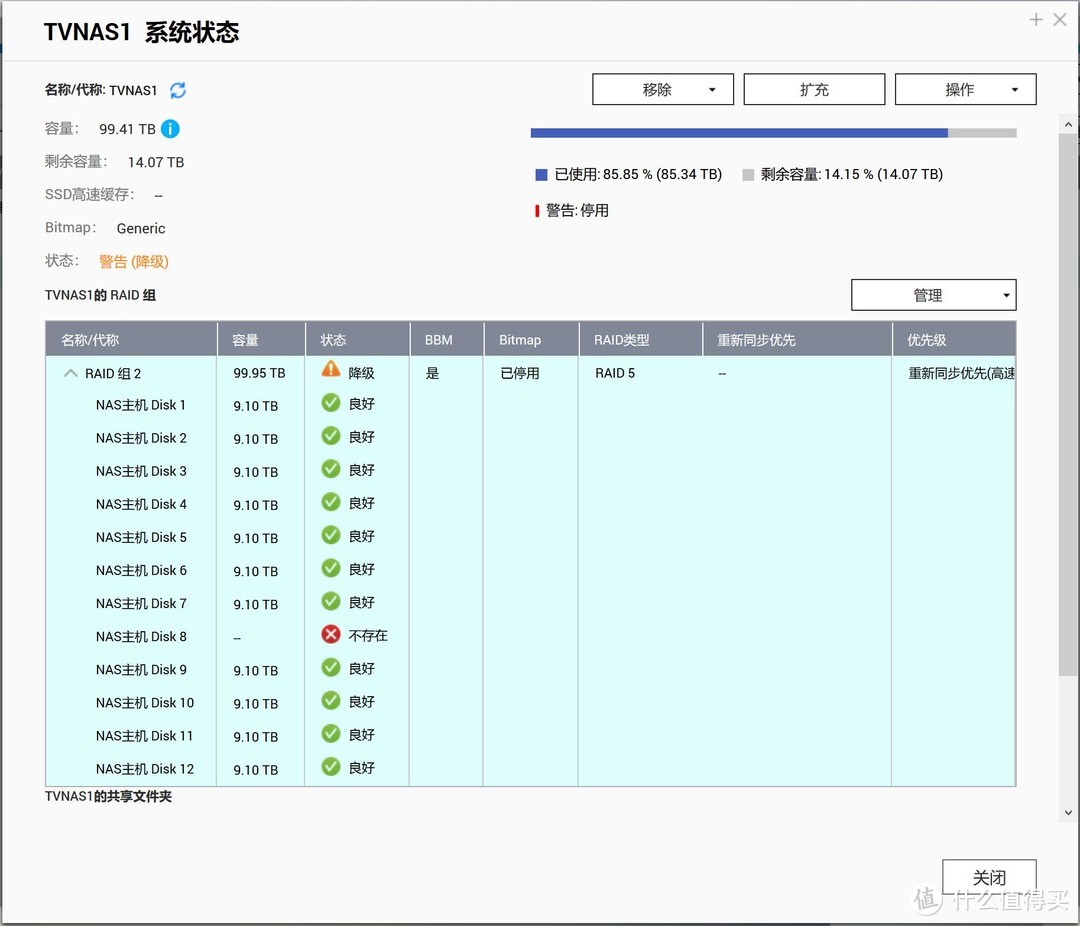 RAID提示Disk8不存在 进入降级模式
RAID提示Disk8不存在 进入降级模式
笔者将经过1个半月转运,恰巧今天刚刚收到的全新WD Easystore 10TB拆盘,得到一块相同型号的WD100EMAZ氦气盘。
 WD Easystore 10TB拆盘
WD Easystore 10TB拆盘
将该盘热插入NAS的8号插槽,系统识别后自动开启重建模式。重建起始时间为北京时间4月3日20:28。重建优先级设定为重新同步优先(高速)模式,初始时重建速度约为165MB/s,据此速度预计的重建时间约为16小时(可见并没有几天乃至十几天那么久)。
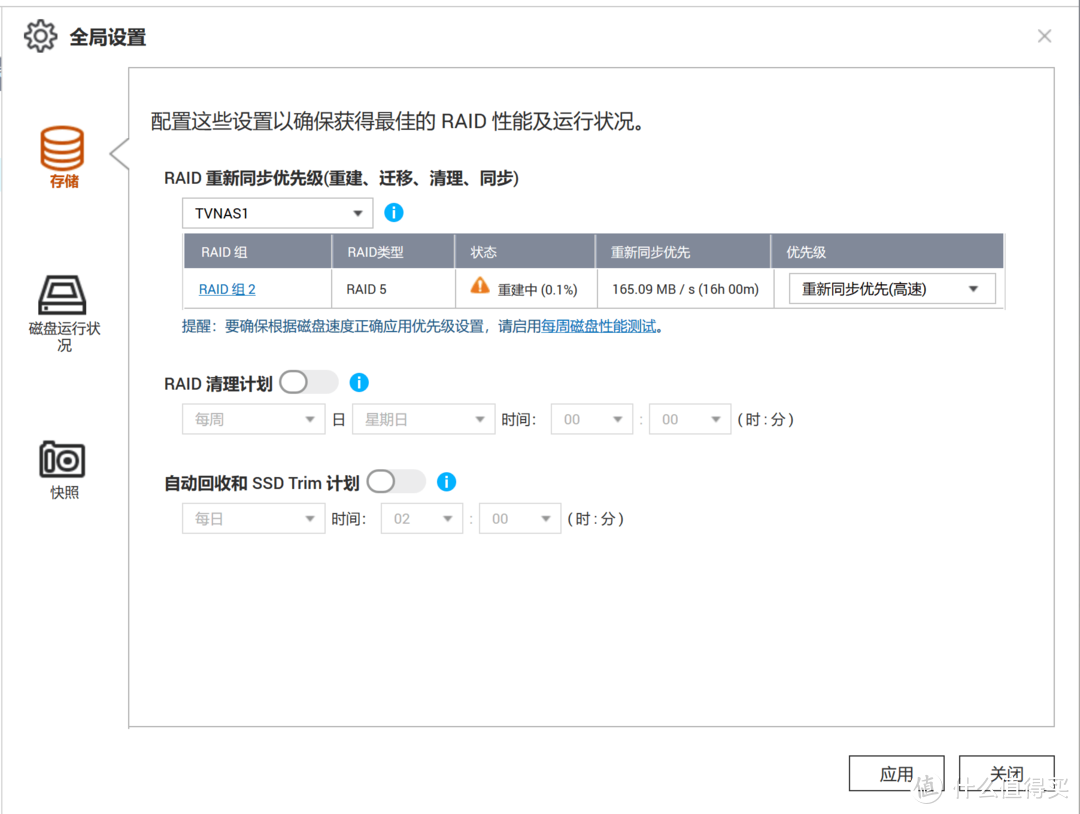 插入硬盘后系统自动启动重建程序
插入硬盘后系统自动启动重建程序
 重建速度与预计完成时间
重建速度与预计完成时间
 重建开始时间
重建开始时间
此时,除8号盘外,其余盘均进行全速读取作业,而8号盘则进行同速写入作业。
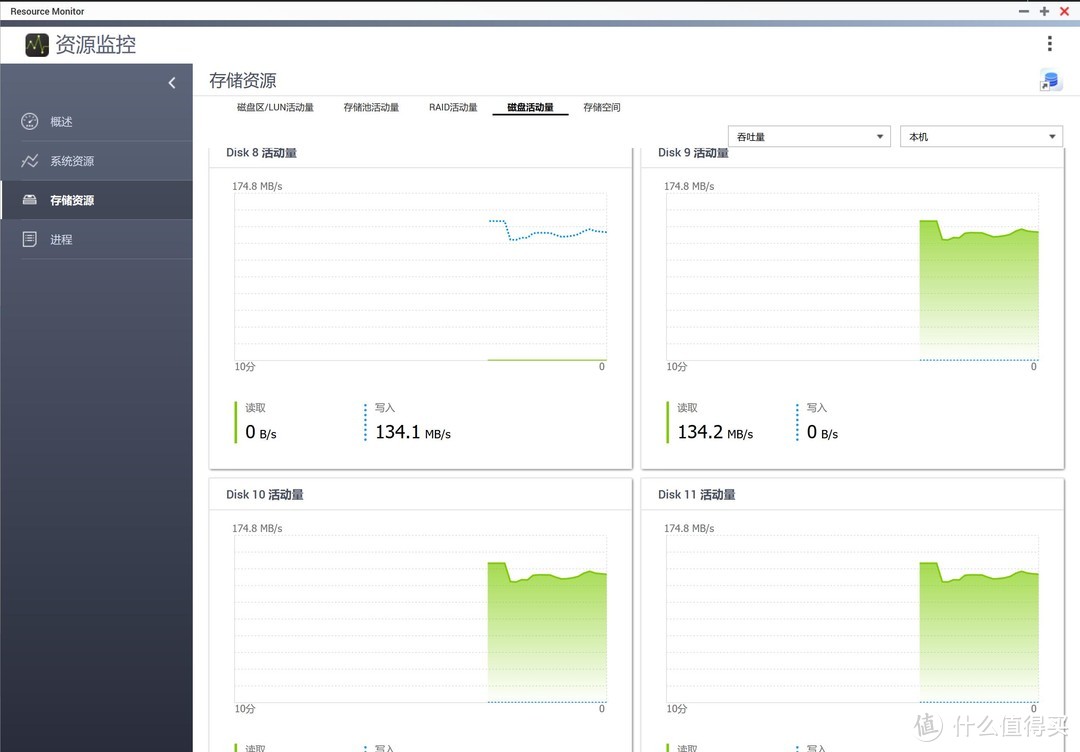 8号盘写入,其余盘读取
8号盘写入,其余盘读取
随着硬盘长时间的读写作业,读写速度会逐渐降低,温度也会有所升高,这也就是大家所提到的重建时的风险。
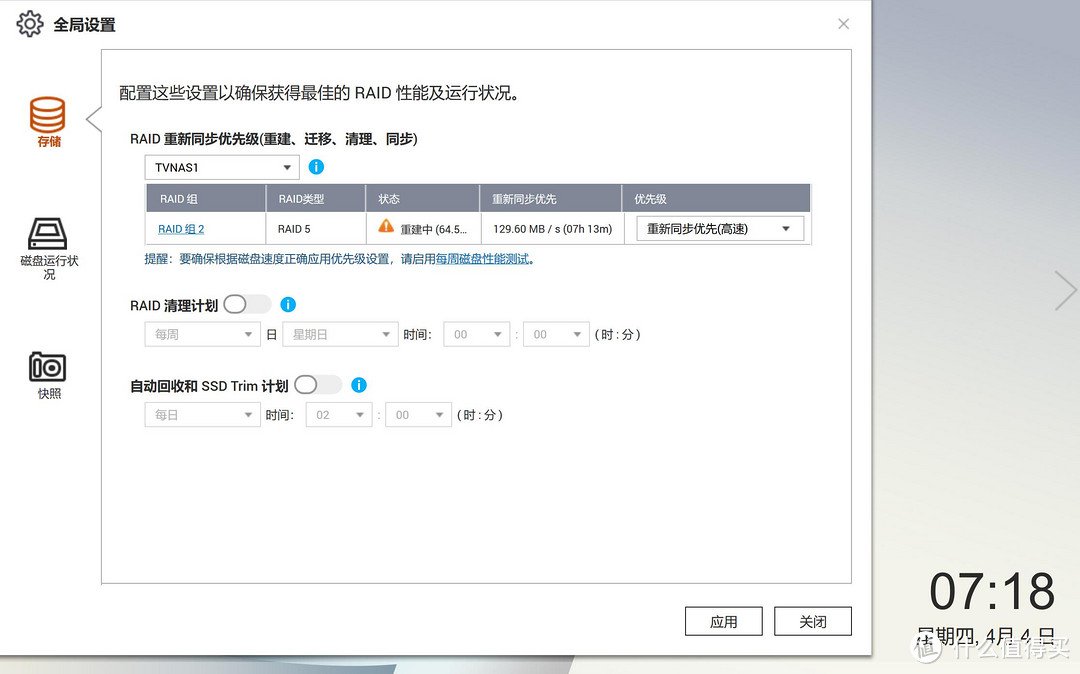 重建11小时完成64.5% 速度降至130MB/s
重建11小时完成64.5% 速度降至130MB/s
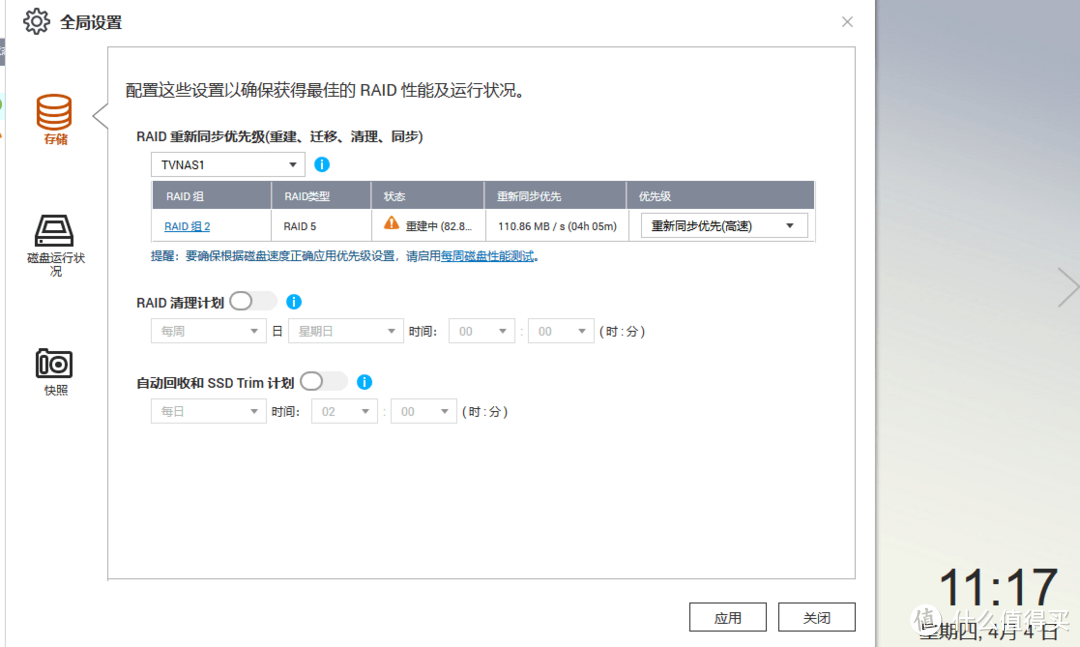 重建15小时完成82.8% 速度降至110MB/s
重建15小时完成82.8% 速度降至110MB/s
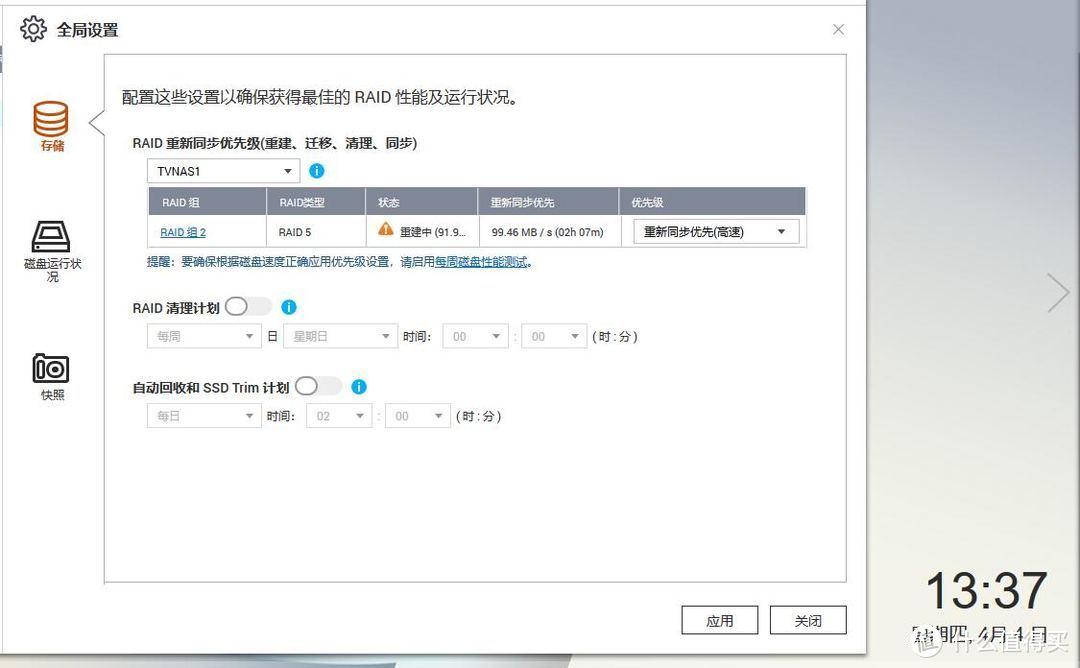 重建17小时完成91.9% 速度降至100MB/s
重建17小时完成91.9% 速度降至100MB/s
 重建17小时后各硬盘温度
重建17小时后各硬盘温度
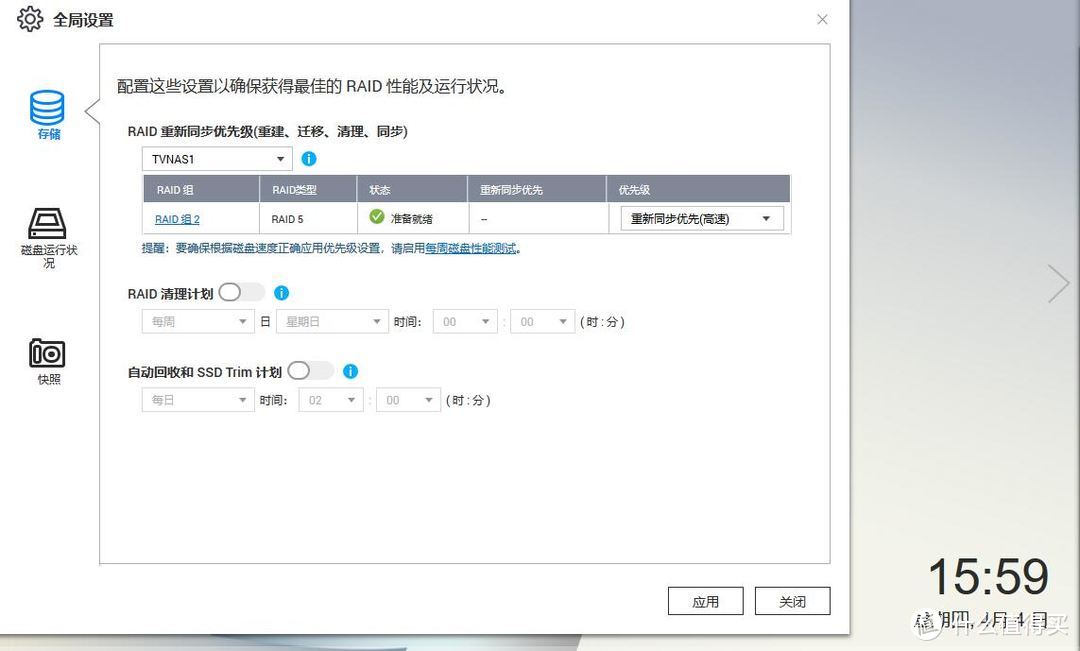 19个半小时重建完成
19个半小时重建完成
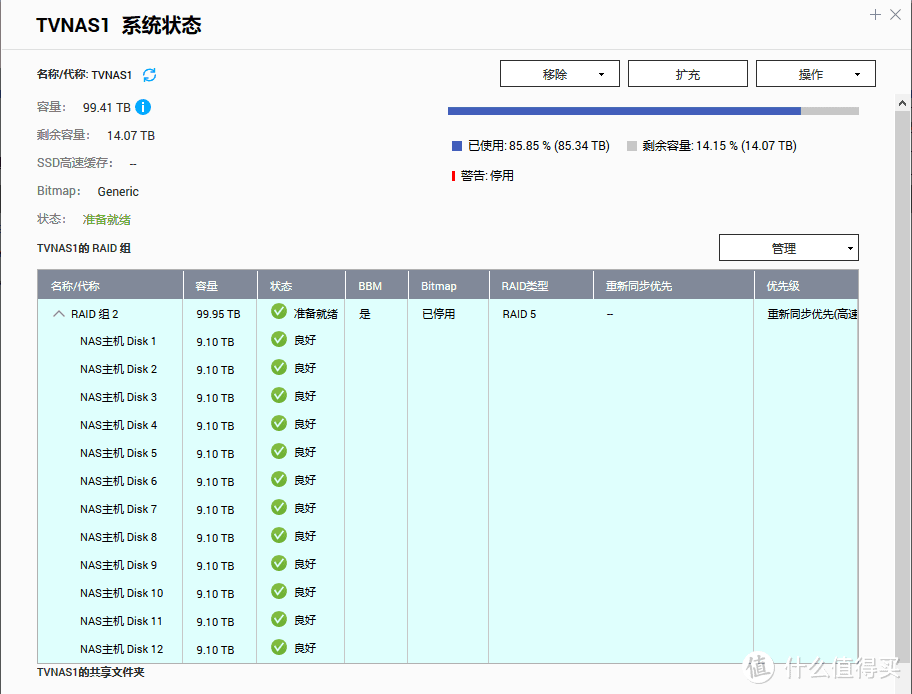 重建完成
重建完成
4月4日15:59 RAID重建完成,历时19小时31分,重建后RAID状态正常、数据正常。
结论
此次实验结果仅仅是一次重建成功的案例,也许只是因为笔者拥有能中双色球三等奖的好运气而已 。所以笔者并不想仅通过此一文就说明RAID5有多么的安全和可靠,只是想向大家客观地展示RAID5也没有想像中的那么危险和脆弱。
。所以笔者并不想仅通过此一文就说明RAID5有多么的安全和可靠,只是想向大家客观地展示RAID5也没有想像中的那么危险和脆弱。
最后,总结三点吧:
1. RAID不是万能的,对于存储方式每个人有着自己的使用情景、习惯和侧重点,因此要寻找一个适合自己的存储方式,平时养成良好的备份习惯最重要;
2. 及时关注RAID状态,当发生降级时及时作好重建或者全盘镜像(没有技术经验的切勿盲目自行操作,应寻求客服或者专业人员的帮助,让专业人作专业事)。因为在RAID降级状态下,仍然可以进行读写操作,所以有好多RAID损毁的案例都是因为没有及时发现冗余磁盘已经损坏,继续带病作业导致磁盘相继损坏;
3. 前辈们告诉我们“实践出真知”,因此在发表言论时要有依据,不要人云亦云。
















小乐CSN
跑了五六年的阵列即便是情况再好风险也是蛮高的吧
重要数据头再铁也不敢这么玩吧
校验提示文案
唐少游
校验提示文案
惆怅而又凄凉
RAID5的原理再简单阐述一下,数据分散写入到每一个数据盘,再进行集中运算,得到一个校验值并写入校验盘。
假设某个数据块是1+2+3,校验值是6。
RAID5的出错情况如下:
数据盘2损坏了,那么重建时则提取校验值6和剩余的健康数据盘1和3,即可计算出损坏数据2。
如果数据盘损坏了两片则无法校验出正确结果,6-3=3,这个3无法分辨是怎么构建出的,可以是03,也可以是12。
那么回归本质,这个失败并不是磁盘损坏造成的!
如果写入某个数据的过程中忽然断电了,那么很可能出现1236当中只写入了13这两个,导致该数据无法恢复。
另一种情况则是比特翻转导致的,磁盘内的磁性物质某一个块发生了损坏,可以理解为坏块。
导致原本是 1236变成了0236,平时使用不受影响,但是一旦需要重建,损坏的又不是那个发生翻转的盘,则出现了036这个局面,导致不可恢复。
RAID5的机制比较坑爹,假设识别到任何一个数据是错误的,则全盘报错无法恢复,所以目前也有一些专业数据恢复的有办法恢复这种情况下的数据,强制跳过该错误。
所以RAID5需要建立在UPS良好的基础之上,并且习惯性备份数据。
校验提示文案
eagleshe
校验提示文案
做IT的农民
校验提示文案
angiie
校验提示文案
逝去岁月
另外,低端的存储设备,因为系统性能的原因,重建时间会加长,所以,如果买的是入门级设备,大容量raid重建还是压力蛮大的。。
校验提示文案
清风道明
校验提示文案
AntonChen
另外组 RAID 最好使用不同品牌,不同批次的硬盘。同品牌同型号同批次的磁盘在同样的环境,同样的通电时间,有很大几率同时损坏。
校验提示文案
p12345
1、RAID硬盘的选用肯定是要统一品牌型号,尽量统一批次。不考虑价格、性能和容量,只考虑安全性的话,sas盘>sata
盘,企业盘>家用盘。企业盘是指西数的金盘、希捷的银河系列之类,西数nas红盘这种是家用盘,不一定好用,我遇到过lsi的一些阵列卡会挑盘,同一个批次的红盘都经常掉盘,就是因为硬盘本身的体质问题。一些专业的存储厂商对硬盘的要求非常严格,一般硬盘稍有异常就报掉盘了,不会等到硬盘死透的。比如emc,我这边在用的两个emc阵列偶提示硬盘故障,我们一般拔出来再插上去就好了。还有一些存储阵列,提示故障的盘,拿出来装家用电脑上照样可以正常使用好几年。
校验提示文案
Ml3b0
1.全新盘。楼主对应真实型号应该是HGST Ultrastar DC HC510/He10,MTBF(平均故障间隔小时数, 单位是百万)为2.5,也就是2500000小时,概率论学的好的可以算算在现有的这些新盘的使用时间内出故障的概率有多大。
2.体质好。第一条说了这块盘的型号,懂行的可以去查查数据,这种盘体质是现有硬盘中各项数据位列前茅的(什么红盘金盘阿鱼阿狼数据拿出来比比全都是弟弟),UBER(不可恢复比特误码率)为15,也就是说10^14内一个bit错误,RAID5恢复成功率的理论值本来也是41%,而不是前一个帖子评论区中使用UBER=14计算出来的0.015%重建成功率。
3.硬盘重建过程完全不对外提供服务,也就是完全不进行额外的读写操作。
4.以上几条合起来,重建失败的概率有多低,反正我是不会算了。
最后贴一下红盘和酷狼的数据吧,依次为He10,红盘,酷狼:
AFR(年化故障率):0.35%、N/A、0.87%
MTBF(平均故障间隔小时数):2.5、1、1
UBER(不可恢复比特错误率):15、14、15
校验提示文案
yinmyu
校验提示文案
johnnyzvip
校验提示文案
pspno1
校验提示文案
名字一直被注册
校验提示文案
喵了个咪83
我说怎么这么多硬盘了,原来是能中三等奖的大神。
校验提示文案
yhsih
校验提示文案
值友6077619293
校验提示文案
momogoutou
校验提示文案
Kenichi_
校验提示文案
半打机车
校验提示文案
值友2398383986
校验提示文案
被现实颠覆的红烧肉
6×14的换硬盘重建,4×14的换硬盘重建,都没问题
校验提示文案
值友9568488052
校验提示文案
值友3718125322
校验提示文案
阁楼听细雨
校验提示文案
蒙多
校验提示文案
拆除魔仙堡的哈士奇
校验提示文案
傲霜视觉
校验提示文案
magnus
2 12*10T的R5还是比较有挑战性的,应该不是日常真这么用吧,盘位足够再多一块冗余盘甚至额外热备一块了
校验提示文案
Simonlqn
校验提示文案
胡图图不剁手
最反感像这样的“实践出真知”。
校验提示文案
阿姆斯特朗
校验提示文案
不怕老鼠的大脸猫猫
校验提示文案
不怕老鼠的大脸猫猫
校验提示文案
BillRocket
校验提示文案
黑夜呐喊
校验提示文案
值友6719308539
校验提示文案
值友1500126218
校验提示文案
手手不乖
校验提示文案