

















































































265
103
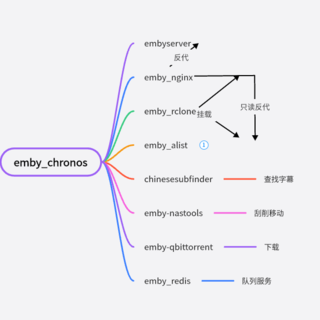
unraid服务器all in one之旅 篇三:jellyfin自动字幕的小脚本
2020-04-23 17:36:53
12点赞
65收藏
18评论
前面写了一个基于subfinder的文章,不过用来不是契合jellyfin
所以抽了点时间写了一个接入到jellyfin的小脚本
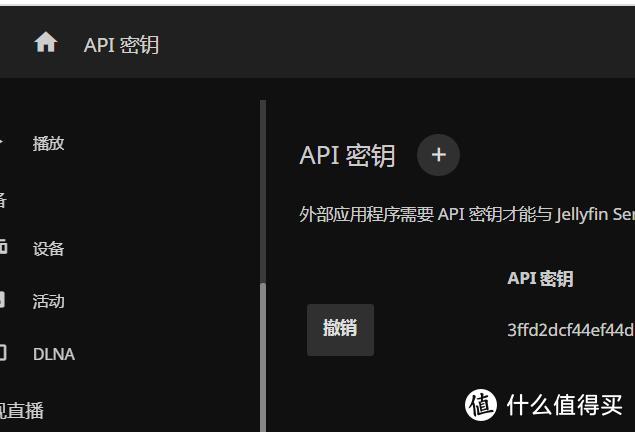
只需要添入APIKEY和服务器IP地址即可
也可以排除不需要查找的文件夹
注意的是这里默认设置不查询现有文件,只负责监控未来新加入文件
py脚本可以挂载到宝塔docker或者Chronos下,
当然也可以在虚拟机里运行,不过要注意挂载文件名称要一致
这里以Chronos docker为例,首先在app商店安装Chronos
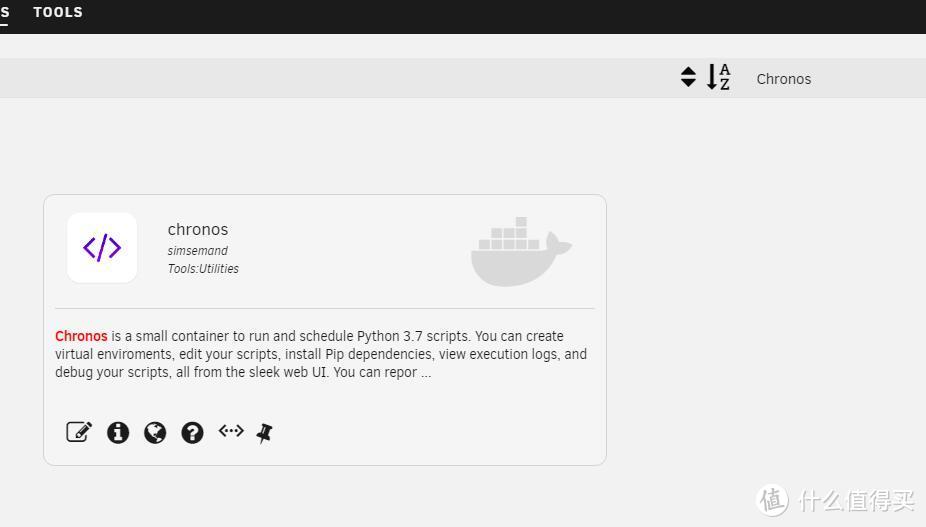
然后修改Chronos设置将jellyfin挂载的媒体文件夹以同样方式挂载,注意挂载文件夹名称要相同
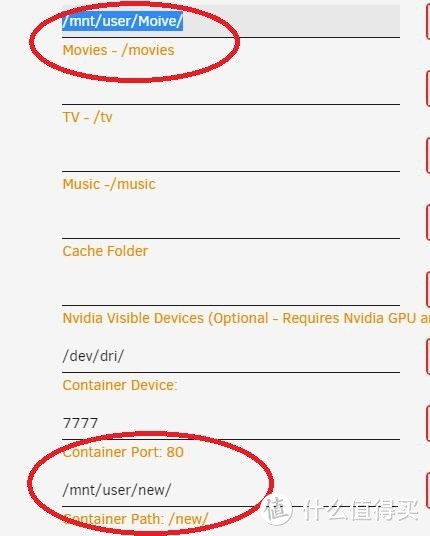
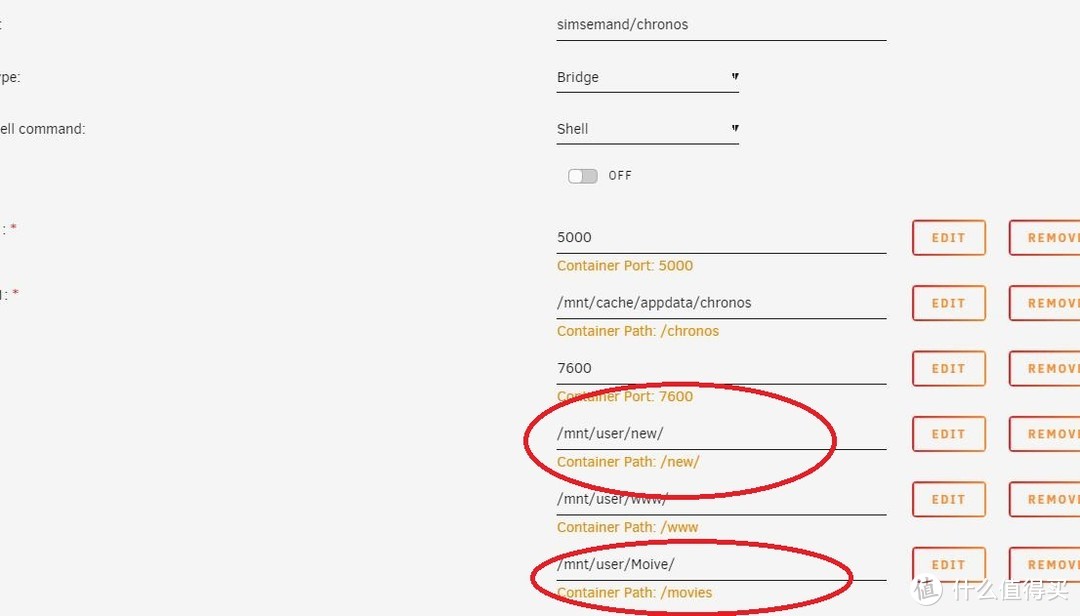
Chronos保持一致
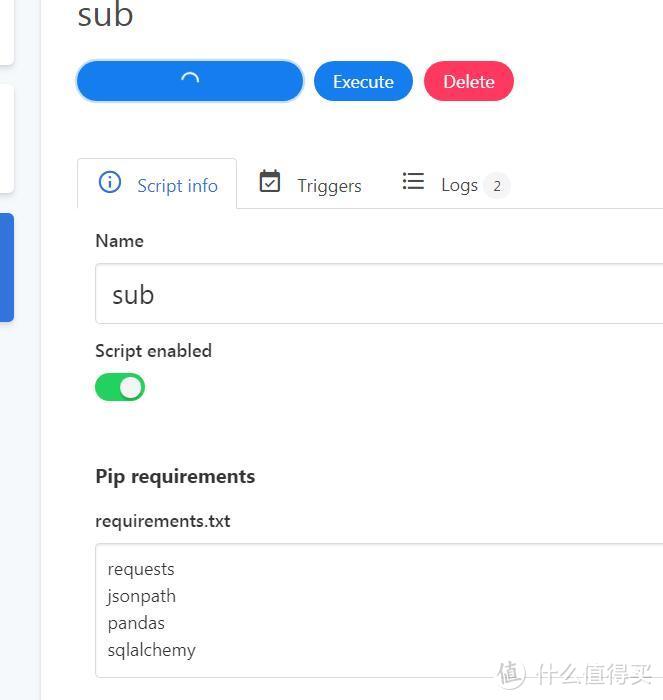
之后新建一个API秘钥,然后在Chronos里新建一个脚本安装以下四个依赖,安装过程需要翻墙
requests
jsonpath
pandas
sqlalchemy
复制脚本进去,填入APIKEY,IP地址,按示例填入排除目录。
#!coding=utf-8
import requests
import jsonpath
import json
import pandas as pd
from sqlalchemy import create_engine
import os
import hashlib
from pathlib import Path
#填入api
api_key = '你设置的APIKEY'
#ip
IP = 'http://172.17.0.1:8096'
#排除目录,非必须
排除目录 = ['/new/JAV_output','/new/rrmovie','/new/failed/tmm']
#默认不查询现有资源,如需查询,建议用subfinder查询指定文件夹
def movname(filePath):
dirlist=[]
for fpath, dirname, fnames in os.walk(filePath):
dirlist.append(fpath)# 所有的文件夹路径
return dirlist
def remov(path):
filename1 =''
templist= os.listdir(path)
nlist=[]
name_list= ['.AVI','.WMV','.MOV','.MP4','.MKV','.FLV','.TS','.avi','.wmv','.mov','.mp4','.mkv','.flv','.ts']
for r in templist:
if any(name in r for name in name_list):
nlist.append(path+'/'+r)
return nlist
def search_subs(videofile):
filehash = video_hash(videofile)
if filehash=='':return ''
else:
root, basename = os.path.split(videofile)
url = 'https://www.shooter.cn/api/subapi.php'
payload = {'filehash': filehash,
'pathinfo': basename,
'format': 'json',
'lang': 'Chn'}
r =requests.post(url,data=payload)
req = r.text
if len(req)>50:
jsonobj = json.loads(req)
Link = jsonpath.jsonpath(jsonobj,"$..Link")[0]
Ext = jsonpath.jsonpath(jsonobj,"$..Ext")[0]
fname,fename=os.path.splitext(basename)
r = requests.get(Link)
with open(root+'/'+fname+'.'+Ext, "wb") as code:
code.write(r.content)
else:
Link =''
print('ok')
return Link
def video_hash(videofile):
""" compute videofile's hash
reference: https://docs.google.com/document/d/1w5MCBO61rKQ6hI5m9laJLWse__yTYdRugpVyz4RzrmM/preview
"""
seek_positions = [None] * 4
hash_result = []
with open(videofile, 'rb') as fp:
total_size = os.fstat(fp.fileno()).st_size
if total_size < 8192 + 4096:return ''
seek_positions[0] = 4096
seek_positions[1] = total_size // 3 * 2
seek_positions[2] = total_size // 3
seek_positions[3] = total_size - 8192
for pos in seek_positions:
fp.seek(pos, 0)
data = fp.read(4096)
m = hashlib.md5(data)
hash_result.append(m.hexdigest())
return ';'.join(hash_result)
def namelist(dirs):
nlist1=[]
dirlist = movname(dirs)
for i in dirlist:nlist1 = nlist1+remov(i)
return nlist1
def re_list(dirlist1):
engine = create_engine('sqlite:///'+dirlist1[0]+'/sub.db')
nlist=[]
for i in dirlist1:
nlist = nlist+namelist(i)
df = pd.DataFrame(nlist)
df.columns=['n']
my_file = Path(dirlist1[0]+'/sub.db')
if not my_file.exists():
df.to_sql('sublist',con=engine, if_exists='append',index=False)
sql = "select * from sublist"
df1=pd.read_sql(sql, engine)
df1.columns=['n']
df2 = df.append(df1)
result = df2.drop_duplicates(subset=['n'],keep=False)
result = pd.merge(df,result,on=['n',])
return result
url = IP+'/Library/VirtualFolders?&api_key='+api_key
r =requests.get(url)
req = r.text
jsonobj = json.loads(req)
Locations = jsonpath.jsonpath(jsonobj,"$..Locations")
dirlist1 = []
for i in Locations:
if i[0] not in 排除目录:
dirlist1 = dirlist1+i
result = re_list(dirlist1)
for i in list(result['n']):search_subs(i)
engine = create_engine('sqlite:///'+dirlist1[0]+'/sub.db')
result.to_sql('sublist',con=engine, if_exists='append',index=False)
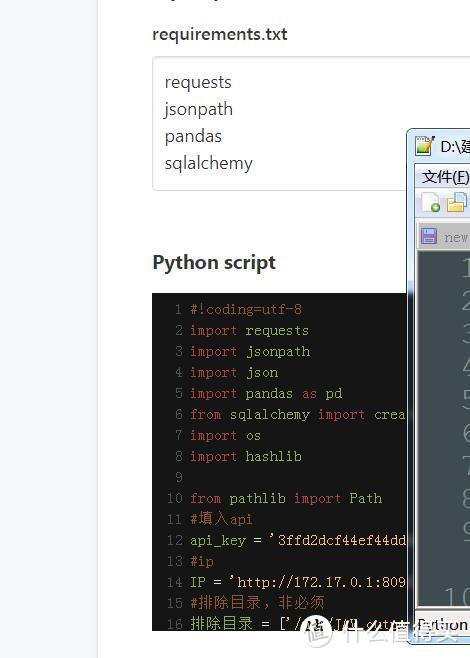
如果是docker jellfyin 这里IP可以不动,默认http://172.17.0.1:8096即可
最后设置一个自己喜欢的间隔时间(不需要过于频繁)
就可以实现自动监控新增的jellyfin媒体目录和文件定时更新字幕了。
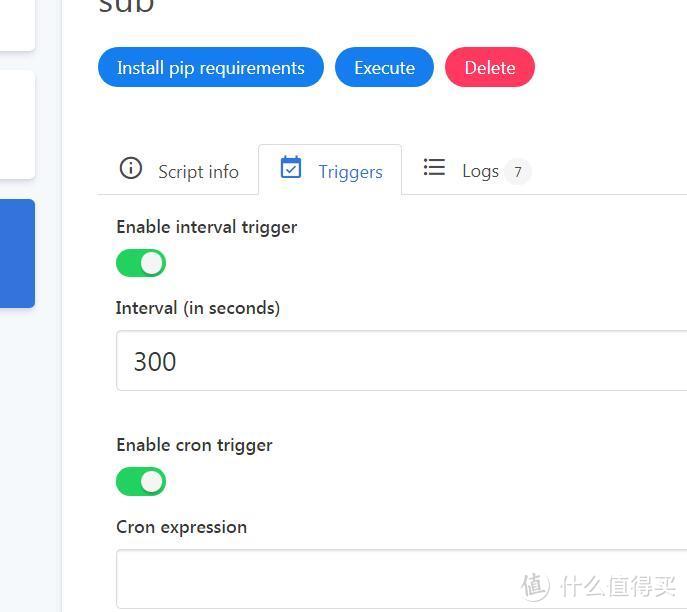 这里设置的是5分钟更新一次
这里设置的是5分钟更新一次
















dkess
校验提示文案
我不是主谋
校验提示文案
lok夜
菜鸡表示看不懂!
校验提示文案
l懒人谈
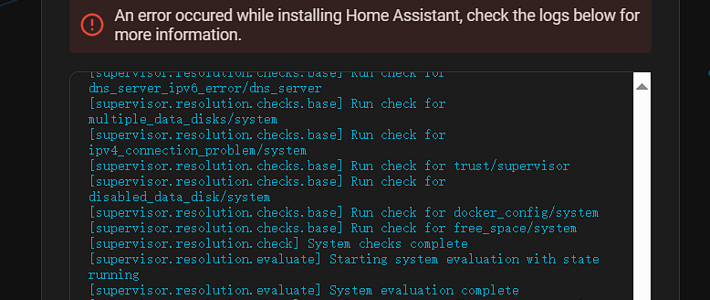
Traceback (most recent call last>:
File "/chronos/scripts/sub/sub.py", line 197, in
jsonobj = json.loads(req>
File "/usr/local/lib/python3.7/json/__init__.py", line 348, in loads
return _default_decoder.decode(s>
File "/usr/local/lib/python3.7/json/decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0>.end(>>
File "/usr/local/lib/python3.7/json/decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value> from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0>
校验提示文案
xx12138
校验提示文案
拉链装
File "/chronos/scripts/sub/sub.py", line 35
dirlist=[]
^
IndentationError: expected an indented block
校验提示文案
拉德布鲁赫信徒
校验提示文案
l懒人谈
校验提示文案
怂系青年
校验提示文案
joker95275
校验提示文案
拉德布鲁赫信徒
校验提示文案
joker95275
校验提示文案
拉链装
File "/chronos/scripts/sub/sub.py", line 35
dirlist=[]
^
IndentationError: expected an indented block
校验提示文案
怂系青年
校验提示文案
xx12138
校验提示文案
l懒人谈
校验提示文案
l懒人谈
Traceback (most recent call last>:
File "/chronos/scripts/sub/sub.py", line 197, in
jsonobj = json.loads(req>
File "/usr/local/lib/python3.7/json/__init__.py", line 348, in loads
return _default_decoder.decode(s>
File "/usr/local/lib/python3.7/json/decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0>.end(>>
File "/usr/local/lib/python3.7/json/decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value> from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0>
校验提示文案
lok夜
菜鸡表示看不懂!
校验提示文案
dkess
校验提示文案
我不是主谋
校验提示文案