





















































































173
71
AI算力军备竞赛开启!英特尔新一代AI PC酷睿Ultra-Lunar Lake登场
2024-06-09 22:41:13
3点赞
3收藏
1评论
关注最近PC市场应该注意到,AI PC成为一个热点。而且传统PC到AIPC的转变过程也异常的快,2023年12月,英特尔
代号为 Meteor Lake 的酷睿 Ultra 1 代AIPC芯片正式发布。仅仅过了半年时间,在 Computex 2024期间,酷睿 Ultra 新一代AIPC芯片又被公布出来了。

Lunar Lake的架构
英特尔新一代的AIPC芯片布局为:面向轻薄本市场的Lunar Lake(移动端),和面向中高功耗市场的Arrow Lake(桌面和移动端),这次公布的就是前者。
CPU
▼计算模块的制造工艺为台积电N3B(部分为台积电N6),史上第一次抛弃自家工艺(还是自家封装)!
 CPU
CPU▼CPU方面仍旧是异构设计,但没有了上代的超低功耗能效核心(Low Power e-core),性能核心也不支持超线程了。英特尔公布参数为:
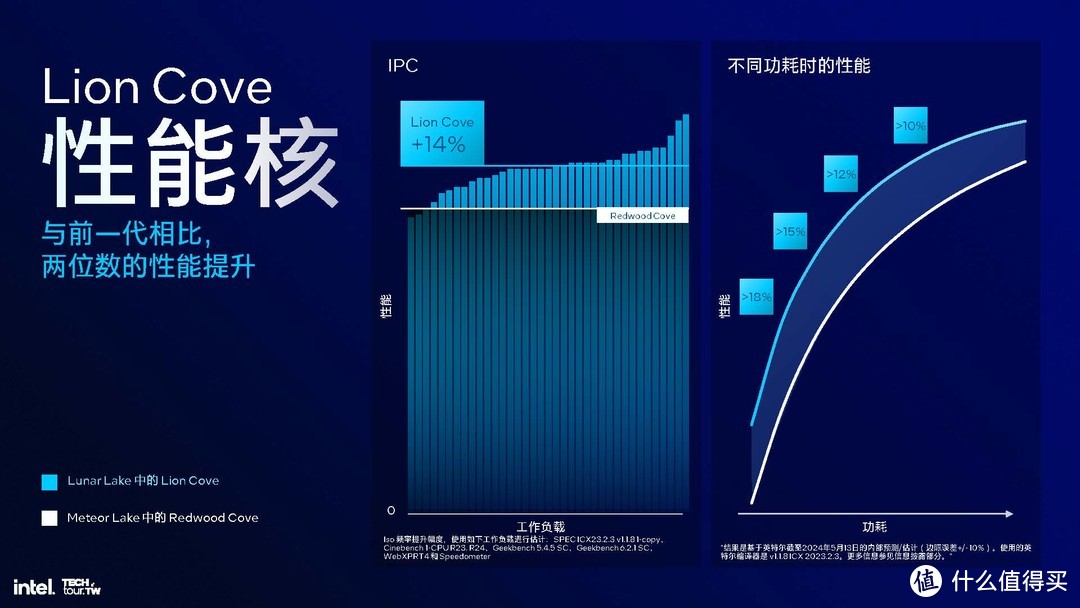
4x Lion Cove 性能核心:IPC 提升 14%
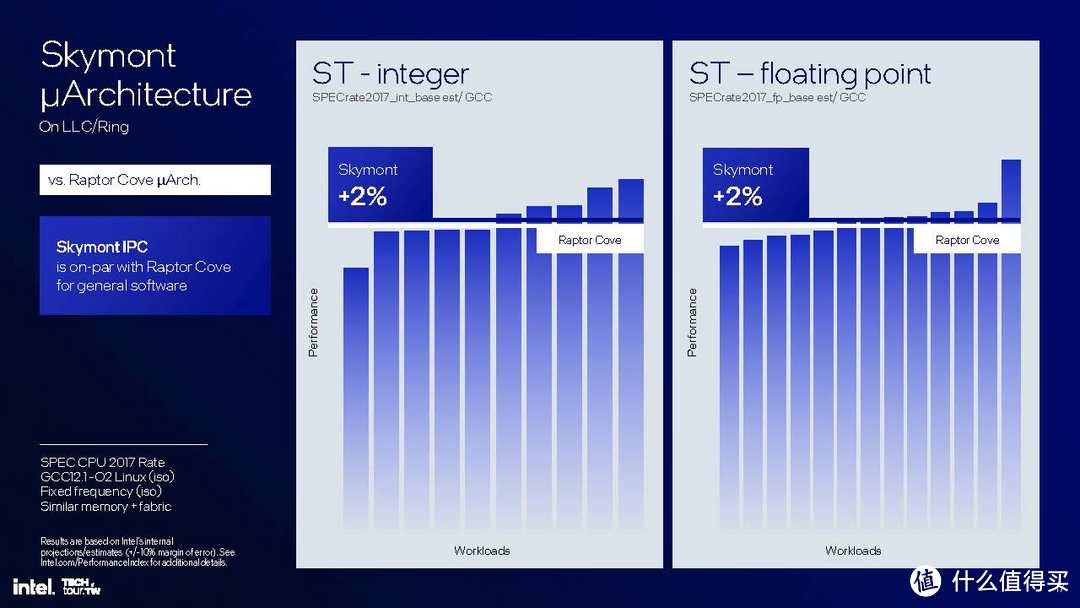
4x Skymont 能效核心:1.38 倍单线程整数性能、1.68 倍单线程浮点性能。
先看性能核心,其实信息并不算多,一共有4个核心,有 2.5MB 的 L2 缓存和 12MB 的共享 L3 缓存。 还引入了AI 频率控制,从100MHz 的频率调整单位精细化到 16.67MHz。唯一提到的性能就是相比上代有 14% 的 IPC 性能提升。
我们知道CPU的性能由IPC、频率和核心数量决定的。作为以低功耗和高能效为设计理念的产品,频率肯定不会有很大的提升(PPT也没提),核心数也就只有4个,再加上不支持超线程。所以顶多也就是单核性能会有同提升,多核性能并不见得比上代高端型号强,也能理解,毕竟还有Arrow Lake呢。
 性能核心
性能核心▼如果你看到调度机制,更不会在乎性能核心了。其首要原则就是在负载满足的前提下优先调用 E 核。而且性能核心和能效核心并没有用Ringbus连在一起,二者是两个独立的集群。在低负载场景下,性能核心簇(CPU+Ringbus)是可以完全关闭的。简单来说就是,除非万不得已,是不会使用性能核心。为啥要这样设计,当然是为了节能了。
 调度机制
调度机制▼看来这下压力来到了能效核心这边了。能效核心也是四个,共享 4MB L2 缓存。按照英特尔的说法,能够与上一代性能核心性能持平;而与Meteor Lake的LP E核相比,整数性能提升38%,浮点性能提升68%,而且用 1/3 的功耗就取得了同样的性能表现。性能提升算非常大了,同时能耗表现也十分让人惊喜。
 能效核心
能效核心如果能效核心真的这么能打,就有一个疑问了。我们知道单个性能核心比上代性能核心提高十几%;单个能效核心接近上代性能核心,那么岂不是Lunar Lake的性能核心只比能效核心十几%吗?而且启动性能核心的几率还不高,那么2个性能核心是不是也够用的?配备4个只是为了跑分?
▼为了追求效能至上,英特尔直接将 LPDDR5X 内存芯片集成于处理器封装之上(最高支持 32GB 容量与 8.5GT / S 速率),并引入了内存侧的缓存区(Memory side cache),这种设计可节约 40% 的 PHY 功耗与 250mm² 的主板面积。从而可以显著提升电池续航,并留出空间给笔记本的其他设计。当然这样也就不支持独立的SO-DIMM内存,无法扩展和升级。
 Memory on Package
Memory on PackageGPU
▼新 GPU 中包含了 8 个 Xe2 核心,8 个光线追踪单元, 8MB L2 缓存,核心和光追单元都有架构上的升级。
 GPU
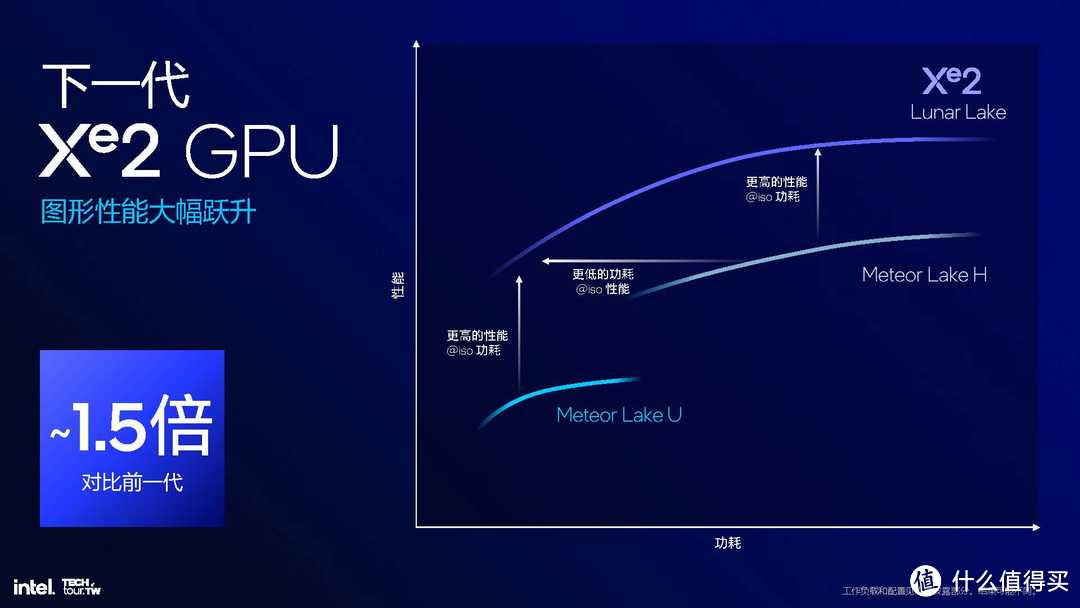
GPU▼GPU的提升是非常巨大的,直接来到了Xe2 核芯显卡,性能是上一代Meteor Lake 核芯显卡的1.5倍,并有更低的功耗表现。最重要的是具有XMX矩阵单元(锐炫独显同源,Meteor Lake则被删掉),能承担游戏中的AI超分等计算任务,从而将更多的GPU算力用于图形处理,以提升游戏性能。同时它能作为第2个AI加速器,这样最高提供67 TOPS的AI算力,相对于游戏性能的提升,AI算力的提升更惊人!
 GPU
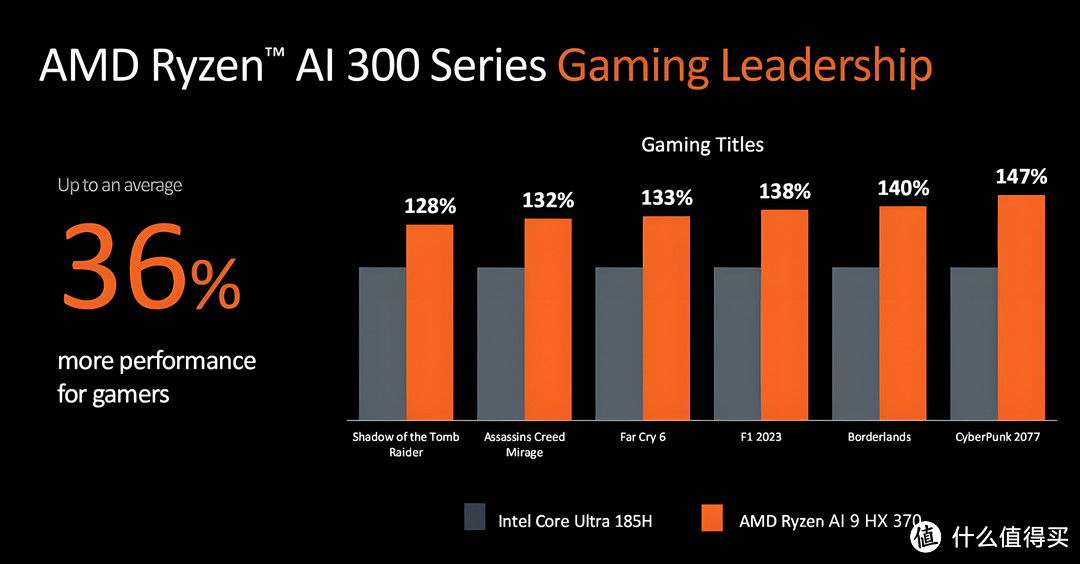
GPU▼之前AMD
锐龙AI 9 HX 370集成的Radeon 890M宣称比Meteor Lake的核显提高了36%的游戏性能;而Lunar Lake则是提高了50%,如果大家的PPT都比较靠谱,那么这次英特尔在GPU方面就要更胜一筹了!
此外,GPU与媒体部分也不再是相互独立的部分,而是与其他计算单元融合在一起。并且也得到了升级,支持 AV1 编解码与 VVC 硬解码(H.266),提供 1x eDP 1.5、DisplayPort 2.1 与 HDMI 2.1 三条显示输出管线。
NPU
目前AI PC芯片可以分成两种。
一是以GPU为主,发挥其在并行计算上的专长,让GPU一边精进图形渲染,一边把AI处理能力做大做强,无需专用NPU也可以很好地支撑端侧AI。
另一种是做法是往PC处理器SoC里塞一个专用AI协处理器NPU,搭配性能越来越强的集成显卡,实现更强的AI算力,做到对高能效与低成本需求的兼顾。
 NPU
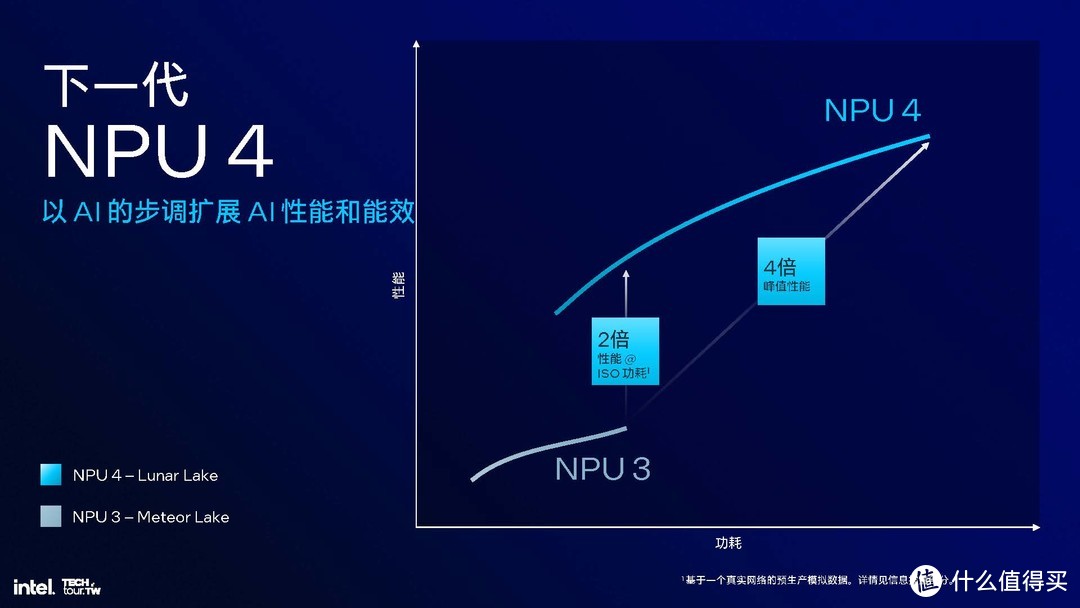
NPU▼英特尔作为老牌的处理器厂商肯定是选择了后者。新一代Lunar Lake来到了 NPU 4.0,在神经处理能力、效率、频率、功耗架构和引擎上都有提升,提升幅度最大应该是12倍的矢量性能和2倍的IP带宽(带宽改进对于更大规模的模型和数据集处理更为重要,如Transformer语言模型应用)。这样 NPU 4.0可提供 48 TOPS AI 算力,相比 Meteor Lake 中的 NPU 3,具有 2 倍能效比与 4 倍的峰值性能。这部分性能较上代的提升也非常大。
 NPU
NPUAI军备竞赛
现在,AI算力的竞争是无比残酷的。

英特尔 Meteor Lake在竞争中的纸面参数并没有什么优势,NPU AI算力仅为11.5TOPS,而AMD 锐龙7040系列的NPU AI算力为10TOPS,8040系列的NPU AI算力为16TOPS ,苹果M3的NPU AI算力18TOPS。
新一代的竞争对手中(仅发布,还未上市售卖),苹果M4的NPU AI算力为38TOPS,高通骁龙X的的NPU AI算力为45 TOPS,AMD 锐龙AI 300的NPU AI算力为50TOPS。英特尔 Lunar Lake的48TOPS NPU AI算力虽然屈居亚军,好在输的的不多,也远超微软的Copilot+PC标准,何况还有未公布的Arrow Lake,还有机会反败为胜。
微软规定所所有运行 Windows 操作系统的 AI PC 都必须具备本地运行 Copilot 的能力以及搭载性能达到 40 TOPS 的神经网络处理单元 (NPU)。
除了NPU算力,还有一个可PK的是总平台 AI算力(整体算力) ,即CPU+GPU+NPU的总算力。不过很多时候CPU、GPU和NPU其实是无法同时协同驱动一个AI进程的,将各计算部件的AI算力进行“加总宣传”,多少有点混淆概念的意味。不过英特尔说很早就在布局异构单元的“AI协同加速”,宣称现在真的可以让开发者用一套API完成对酷睿Ultra里CPU、GPU、NPU的同时调用。先抛开事实不谈吧,让我们看看各家总平台 AI算力如何:
AMD的锐龙7040的总平台 AI算力为33TOPS
英特尔Meteor Lake 的总平台 AI算力为34TOPS
AMD锐龙8040的总平台 AI算力为39TOPS
高通骁龙X 的总平台 AI算力为75TOPS
AMD锐龙AI 300的总平台 AI算力为80TOPS
英特尔Lunar Lake总平台 AI算力为 120 TOPS
这方面Lunar Lake确实遥遥领先,最大的功臣肯定是GPU了,应该没有其它的GPU提供这么高的AI算力(苹果的数据没查到,但应该不会超过Lunar Lake)。如果是需要GPU 运行大吞吐量的 AI 任务,肯定是Lunar Lake会有优势。当然如果真是CPU+GPU+NPU同时运行AI应用,笔记本的续航会尿崩,只是适合能外接电源的应用场合。
CPU 主要负责低延时任务,GPU 运行大吞吐量的 AI 任务,NPU 支持低功耗持续的 AI 计算。
 总平台 AI 算力
总平台 AI 算力AI PC对普通消费者的意义
AI PC可以支持大语言模型在终端侧运行;可以在使用Stable Diffusion,Adobe Premier Pro,Adobe Lightroom Classic创作时获得更好的性能;可以将更多场景中部署端侧AI,进一步摆脱对云侧的依赖,避免隐私泄露和安全威胁。但这些貌似都是和专业人士和创作者有关,对于更普通的消费者,AI PC到底有没有用呢?
随着AI算力的大幅提升,NPU的应用也将不再局限于一些持续性低负载场景(比如视频会议),而是有了更多可能,让AI加速更多普通人群常用的应用。同时能效更高的AI运算在更多场景中部分取代CPU、GPU,大大提升笔记本的续航能力。这些体验对于普通使用者,尤其是需要移动办公娱乐的人们来说意义更大。
总之,Lunar Lake的GPU最让人惊喜,NPU也非常不错,CPU嘛,就不要有过多期待了。整体设计以高能效为目标,比如有点费点的超线程就被取消了,加上NPU的性能提升,理论上应该会是一个低功耗长续航的移动端产品。
但同时它也保留了稍微有点多的4个性能核心,和一个游戏性能和Ai算力都非常出色的GPU,貌似在可以接电源的情况下可以达到更好的性能。但其最终的产品形式又是以轻薄本为主,让人有点担心轻薄本的散热规模是否能让CPU和GPU发挥出全部分性能,这个也只能等到真正产品发售后才知道了。
Lunar Lake预计将于 2024 年第三季度出货,刚才漏讲了IO,这里补一下:提供4条PCIe 5.0,4条PCIe 4.0总线通道,可以连接2块SSD,或者1块SSD和其他扩展。同时原生支持Wi-Fi 7,原生支持Thunderbolt 4,全新的Thunderbolt Share功能。
在Computex 2024,我们看到了几款使用 Lunar Lake 的华硕
产品,包括 轻薄本Zenbook S 14 ,商务本ExpertBook P5,和一款NUC产品:Lunar Canyon。等到双十一前后我们再详细聊聊实际的产品,毕竟以上都是PPT嘛!
 ExpertBook P5
ExpertBook P5如果是刚需要买AI性能更强的轻薄本,现在就只能买英特尔 Meteor Lake 笔记本
和AMD锐龙8040(还有7040)笔记本了。
对了,差点忘了,还有苹果M3。

















含笑三不沾
校验提示文案
含笑三不沾
校验提示文案